- Published on
Generating unique IDs in a distributed environment at high scale.
Recently, I was working on an application which had a sharded database, required generating unique IDs at scale that could be used as a primary key. This is commonly asked and an interesting system design problem. In this article, I will discuss the possible solutions with their pros and cons.
My Requirements -
I need to design a system which generates :
- Unique Ids
- should be sortable by time
- should ideally be 64 bit (for smaller indexes and better storage in systems like redis)
- Highly available and scalable
Possible solutions
- Auto Incrementing Ids
Pros
- The simplest approach ever
- Sorted in nature
Cons
- Fails in case of sharded databases
- Auto-incrementing ids are leaky
for example, I have a social media website where profile page looks like -
https://mysocialmedia.com/profile/1234Here 1234 is the auto incrementing id which is assigned to the profile. If I wait for some time and create a new profile, I can compare these profile ids and know how many profiles were created during that time. It might not be a very sensitive information but It's a bad practice, a system exposing information that It didn't intend to disclose.
- Current Timestamp
Pros
- super simple approach
- Always unique, works for small applications, single process, non-sharded dbs
Cons
- Does not work for sharded dbs, fails very badly at scale and in case of multiple processes
- Again leaky, not a good practice
- UUIDs
UUIDs (Universally Unique Identifier) are 128-bit hexadecimal numbers that are globally unique.
Pros
- Totally independent (uses current timestamp, process id, MAC address) and works very well for sharded databases at high scale
- Always unique, Negligible chances of collisions (same UUID generating twice)
- If we use timestamp as the first component of the ID, the IDs remain time-sortable.
Cons
- UUIDs require more space (128 bit) just to make reasonable uniqueness guarantees.
- Due to its big size, it doesn't index well. When our dataset increases, index size increases and query performance takes a hit.
- Some UUID types are completely random and have no natural sort.
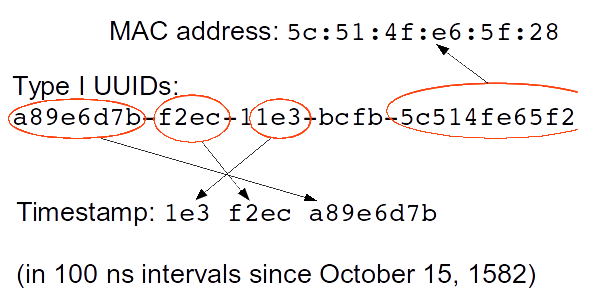
- It has always been a discussion that some of the UUID package types are leaky as they expose timestamp, mac address information. Although v5 UUIDs are generated by hashing and throwing away some bits which ensures that we have no chance of recovering any information from it.
Nano ID can also be an option which are ~40% faster and lighter than UUID packages. They use hardware random numbers to prevent collisions instead of using timestamp, mac address etc. Its simpler + secure but again, size is big and reducing sizes comes with a cost of less uniqueness.
- MongoDB Object IDs
MongoDB object Ids are 96 bit hexadecimal numbers, made up of -
-
32 bit (epoch timestamp in seconds)
-
24 bit (machine identifier)
-
16 bit (process id)
-
24 bit (counter, starting with a random value)
Again, the size is relatively longer than what we normally have in a single MySQL auto-increment field (a 64-bit bigint value).
- Database ticketing server
This approach uses a centralized database server to generate unique incrementing ids. In simple words, a table which stores the latest generated ID and every time a node asks for an ID, it increments the values sent back as a new ID.
Pros
- works very well for sharded database and at scale
- short length, index pretty well, does not hit query performance in case of large dataset
Cons
- Single point of failure as all nodes rely on this table for the next id.
- Ticketing servers can become a write bottleneck at scale as it might not be suitable when writes per seconds are very high as it will overload the ticketing server and degrade the performance.
- Requires extra machines for ticketing servers
- If using a single db for the same, there is a single point of failure and if we use multiple dbs, we can not guarantee that ids are sortable over time.
- Twitter Snowflake
This is a dedicated network service for generating 64-bit unique IDs at high scale. It is developed by twitter to generate unique ids (for tweets, direct messages, lists etc).
These unique ids are 64 bit unsigned integers, which are based on time, instead of being sequential. It is made up of -
- Epoch timestamp in millisecond precision - 41 bits (gives us 69 years with a custom epoch)
- Configured machine id - 10 bits (gives us up to 1024 machines)
- Sequence number - 12 bits (A local counter per machine that rolls over every 4096)
The extra 1 bit is reserved for future purposes. (signed bit, Always set to 0 for now)
As this uses timestamp as its first component, they are time sortable. This is the best solution I could find meeting all my requirements. Our microservices can use this to generate IDs independently.
More info about Twitter Snowflake
Instagram also built their own stack for generating unique ids, which looks similar to Twitter snowflake approach but avoids introducing additional complexity (Snowflake servers) into their architecture.
Conclusion - System designing is more of a discussion. These are my personal views. Feel free to correct me.