- Published on
How database indexing actually works internally?
Let's start with a simple example showing why you would need indexing in a database.
Suppose we have a table called costing with three columns company_id, unit, unit_cost which is completely unordered.
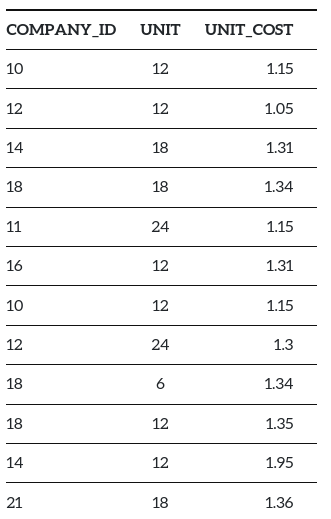
If we run the below query -
SELECT company_id, units, unit_costFROM costingWHERE company_id = 18The database would have to go through all the records one by one, in the order they appear to search for the matching datasets. It will become more and more time consuming once the table size increases.
Visual Representation of the Query execution
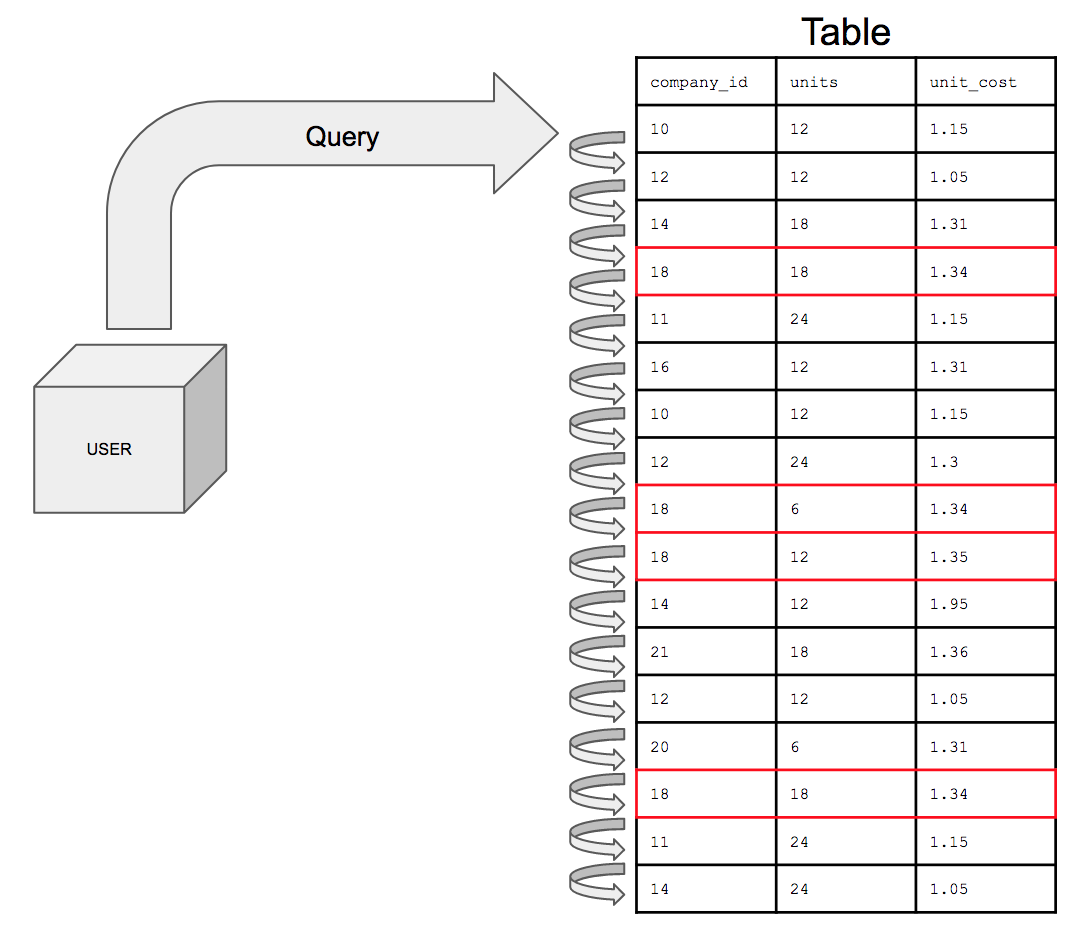
It’s almost like looking through the entire database with the human eye – very slow and not at all sleek. This is what is called a full table scan.
So here, indexing comes into picture. What indexing does is, sets up the column your search conditions are on, in a sorted order to assist in optimising query performance.
With index on company_id, table would look like this -
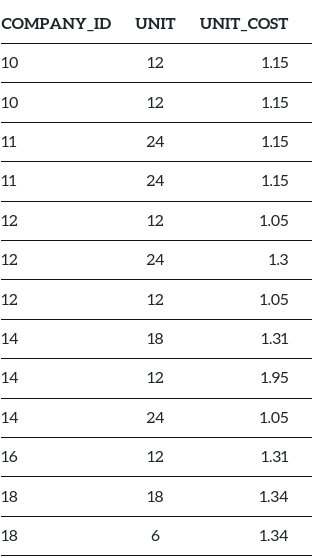
Now, due to sorted order, the database knows which records to examine and when to stop.
The main point of having a index is to cut down the number of records/rows in a table which needs to be examined by the database, to speed up the searching queries.
So, How indexing actually works?
Well, first off, the database table does not reorder itself when we put index on a column to optimize the query performance.
An index is a data structure, (most commonly its B-tree
Its balanced tree, not binary tree) that stores the value for a specific column in a table.
The major advantage of B-tree is that the data in it is sortable. Along with it, B-Tree data structure is time efficient and operations such as searching, insertion, deletion can be done in logarithmic time.
So the index would look like this -

Here for each column, it would be mapped with a database internal identifier (pointer) which points to the exact location of the row. And, now if we run the same query.
Visual Representation of the Query execution
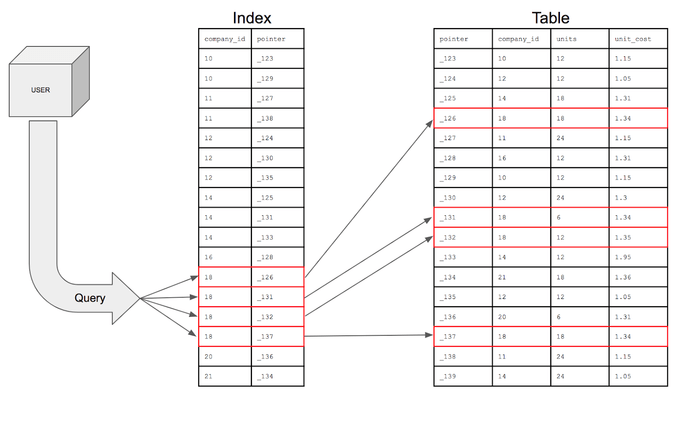
So, indexing just cuts down the time complexity from o(n) to o(log n).
What are other types of indexes?
- Hash Index -
Hash table are another data structure which are used in indexing. The reason behind hash indexes are used is because hash table are extremly efficient when it comes to searching values (0(1) time complexity).
So now, if run the query which we discussed earlier, instead of o(log n) search, hash index will get the pointer value from hash table directly in o(1) and query would be much faster.
So, why not use hash index everywhere if it is so fast?
Well, there are some disadvantages of hash index. These are un sorted in manner and there are many types of queries which hash indexes can not even help with. For example, suppose you want to find out all of the companies which has company_id less than 40. How could you do that with a hash table index? Well, it’s not possible because a hash table is only good for looking up key value pairs – which means queries that check for equality (like “WHERE company_id = 18”).
This is why hash indexes are usually not the default type of data structure used by database indexes – because they aren’t as flexible as B- trees when used as the index data structure.
- R-Tree -
These indexes uses R-tree data structure and these are used to help with spatial problems such as "find all bus stand within 5KM of me".
- Bit map index -
These indexes works well on column that contain Boolean values (true or false).
What is the cost of indexing?
- Indexing makes "reads faster but writes slower". Every write, update, insert operation to the table, will have to be done to the index also.
Thing to note, MySQL put indexes in memory.
- Another thing is space, the larger our table, the larger our index.
The most common pitfalls of Indexing
Most of the developers think, indexing is super cool. Put indexing on any column and query performance is gonna sky rocket but this is not the case. We need to consider a few things while putting index on columns (Here we are going to talk about MySQL).
For example -
Let's say, we have a table called "orders". It has roughly 2M rows with column order_id, amount & createdAt. We need to find the sum of all orders amount, placed in 2020.
So, we might do something like this -
SELECT total(amount) FROM orders WHERE YEAR(createdAt) = 2020;It gives us right output but query is pretty slow. So, we put index on column "createdAt" and see the performance. BUT query is still taking the same time. If we look at query execution, we find that we are still doing a full table scan. So, for some reason, even though we have an index, its not being considered.
It brings us to the first pitfall of indexing which is functions. If we use function inside "WHERE" clause, we will loose the ability to use index.
It's worth noticing that MySQL v8.0.13 and above now support functional indexes.
There are other ways too to write this query.
SELECT total(amount) FROM orders WHERE createdAt BETWEEN '2020-01-01 00:00:00' AND '2020-12-31 23:59:59';But, It will still do a full table scan because we are using "amount" column to calculate the total. So, we need to put an index on "amount" column too.
Along with this, order of indexes also matters a lot in query performance.
To confirm, index is actually being considered or not, add "EXPLAIN" before the SQL query and check the "type" and "rows", which database is looking at to fetch the result.
Thanks for reading.
Image Source - Chartio.